A/B-тестирование давно стало обязательным элементом продуктовой разработки. Его используют стартапы и корпорации, продуктовые и маркетинговые команды, growth-направления и UX-исследователи. При этом реальная ценность A/B-тестов часто оказывается значительно ниже ожидаемой. Эксперименты запускаются, цифры считаются, отчеты готовятся, но продуктовые решения либо не меняются, либо принимаются по тем же причинам, что и раньше.
Проблема здесь не в статистике и не в инструментах. Она в логике. A/B-тестирование часто воспринимают как техническую процедуру, а не как управленческий механизм. В результате эксперименты превращаются в фоновую активность, которая создает иллюзию data-driven подхода, но не снижает неопределенность.
Чтобы A/B-тесты действительно помогали принимать продуктовые решения, они должны быть встроены в контур управления. Эксперимент начинается с вопроса, а заканчивается выбором. В этой статье мы подробно разберем логику A/B-тестирований и покажем, как именно эксперименты могут стать инструментом принятия решений, а не самообмана.
Поверхностная логика критики PM
Когда A/B-тесты не приводят к заметным улучшениям, в фокус внимания быстро попадает Product Manager. Его считают ответственным за гипотезы, за метрики и за интерпретацию результатов. Если рост не случился, значит PM плохо справляется со своей работой. Это объяснение кажется логичным, но оно поверхностно.
Во многих командах от PM ожидают, что он будет «генерировать тесты» и показывать активность. Количество экспериментов становится косвенной метрикой эффективности. В такой среде PM вынужден оптимизироваться под процесс, а не под результат. Он запускает тесты, даже если они не влияют на ключевые решения.
Ошибка мышления здесь в том, что ответственность возлагается на человека, а не на систему. Даже сильный PM не сможет извлечь пользу из A/B-тестирования, если эксперименты не связаны с реальными управленческими выборами. В итоге проблема выглядит как «плохой PM», хотя на самом деле это системный дефект.
Когда нет управления, PM становится виноватым
Контур управления через A/B-тестирование должен быть замкнутым. Он начинается с бизнес-вопроса, проходит через гипотезу и эксперимент и заканчивается решением. Если на любом этапе связь разрывается, эксперимент теряет смысл.
Чаще всего разрыв происходит в двух местах. Первый - на входе. Эксперименты запускаются без четкого вопроса. Команда тестирует идеи, элементы интерфейса или тексты, не понимая, какую неопределенность она хочет снизить. В таком случае любой результат легко интерпретировать произвольно.
Второй разрыв происходит на выходе. Тест завершен, данные получены, но решение уже принято заранее или откладывается. Результат становится «интересным наблюдением», а не основанием для действия. PM формально сделал свою часть работы, но продукт не изменился.
В такой системе Product Manager действительно выглядит слабым. Но проблема не в его компетенциях, а в отсутствии управленческой логики. Пока контур не замкнут, A/B-тестирование не может выполнять свою функцию.
Провальные действия
A/B-тестирование невозможно без ошибок. Любая гипотеза - это предположение о поведении пользователей, а человеческое поведение редко подчиняется простым моделям. Ошибка сама по себе не является признаком плохой работы.
Допустимы ошибки в ожиданиях. Команда может ожидать значительного эффекта, а получить нулевой результат. Это не провал, если команда понимает, почему эффект не проявился и использует это знание в дальнейшем.
Допустимы ошибки в выборе формата изменения. Иногда гипотеза верна, но реализация слишком слабая, чтобы повлиять на поведение. Такой результат помогает скорректировать подход и сделать следующий эксперимент сильнее.
Ошибки допустимы до тех пор, пока они уменьшают неопределенность. Если после теста команда лучше понимает пользователя, контекст или ограничения продукта, эксперимент был полезен независимо от цифр.
Почему идеальность вреднее ошибок
Ошибка превращается в некомпетентность тогда, когда команда перестает учиться. Если эксперименты повторяются по шаблону, а выводы не накапливаются, A/B-тестирование становится ритуалом.
Еще один признак некомпетентности - подгонка результатов. Когда тест останавливают в удобный момент, меняют метрики по ходу эксперимента или выбирают выгодные сегменты, данные перестают быть источником знания.
Критичным является и отсутствие последствий. Если результат теста не может изменить решение, эксперимент не должен был запускаться. В противном случае команда тратит время на активность, которая не влияет на продукт.
Как это выглядит вне теории и фреймворков
В discovery A/B-тестирование часто используют как замену исследованиям. Команда сразу переходит к тестированию решений, не разобравшись в причине поведения пользователей. Гипотезы формулируются поверхностно и плохо объясняют мотивацию.
В такой ситуации любой результат можно объяснить задним числом. Рост метрики считается подтверждением идеи, падение списывается на шум. Эксперимент не дает нового знания.
Зрелый подход предполагает, что A/B-тест проверяет конкретную версию ответа на вопрос о выборе пользователя. Тогда любой результат - положительный или отрицательный - расширяет понимание проблемы.
В delivery A/B-тесты часто конфликтуют с планированием. Решение уже заложено в roadmap, а эксперимент нужен лишь формально. Его либо завершают досрочно, либо игнорируют результат.
Это подрывает доверие к данным. Команда привыкает, что тесты не влияют на решения, и начинает относиться к ним как к обязательному ритуалу.
Зрелый процесс предполагает, что эксперимент может изменить планы. Если этого не происходит, A/B-тестирование теряет управленческую ценность.
В коммуникации проблемы проявляются через споры о цифрах. Разные команды интерпретируют один и тот же результат по-разному и используют данные как аргумент в дискуссии.
Без заранее согласованных правил анализа данные становятся инструментом манипуляции. Каждый выбирает тот срез, который подтверждает его позицию.
Зрелая логика A/B-тестирования снижает пространство для таких конфликтов, потому что правила интерпретации определены заранее.
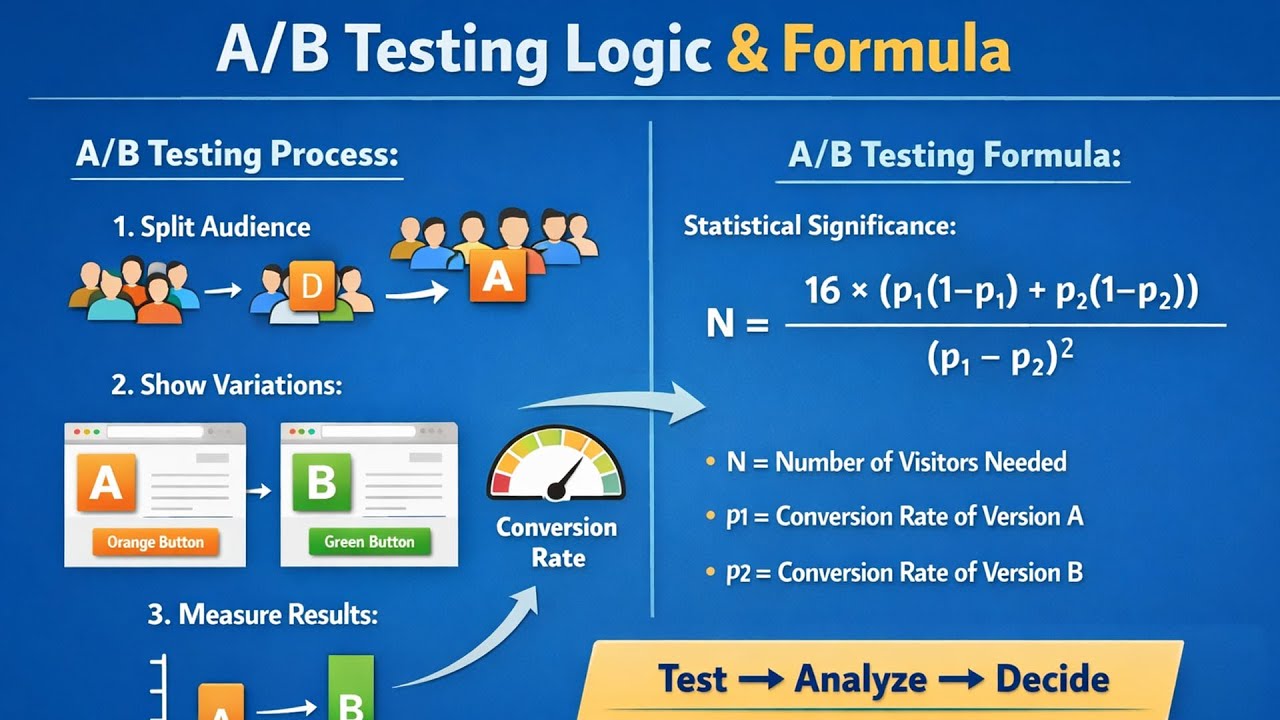
Что говорят инструменты
Зрелость A/B-тестирования всегда проявляется не в количестве экспериментов, а в том, какие артефакты сопровождают процесс. В зрелой системе эксперимент начинается задолго до настройки вариантов и заканчивается не отчетом, а решением. Все ключевые шаги зафиксированы и понятны участникам.
Первый базовый артефакт - формализованный бизнес-вопрос. Он описывает, какую неопределенность команда пытается снять. Это не формулировка уровня «увеличить конверсию», а конкретный вопрос о выборе пользователя, его мотивации или барьере. Без этого вопроса эксперимент не имеет направления.
Второй артефакт - явная гипотеза, связанная с этим вопросом. Гипотеза объясняет, почему предполагаемое изменение должно повлиять на поведение пользователя. Она задает логику интерпретации результата и не позволяет подменять выводы задним числом.
Третий артефакт - заранее зафиксированное решение. Команда договаривается, что именно она будет делать при разных исходах теста. Это превращает эксперимент в управленческий инструмент и защищает от ситуации, когда данные есть, а действий нет.
10 провалов, по которым сразу видно плохого PM
Провал 1. Тест без вопроса.
Эксперимент запускается без понимания, зачем он нужен.
Провал 2. Гипотеза в виде изменения.
Описывается кнопка или текст, а не ожидаемое поведение.
Провал 3. Метрика ради метрики.
Выбирается показатель, который не влияет на решение.
Провал 4. Нет критериев успеха.
Результат невозможно однозначно интерпретировать.
Провал 5. Преждевременная остановка.
Тест завершается при первом удобном сигнале.
Провал 6. Подгонка сегментов.
Данные режутся до получения «красивого» эффекта.
Провал 7. Игнор побочных эффектов.
Смотрят на рост одной метрики и не видят ущерб в других.
Провал 8. Отсутствие фиксации выводов.
Результаты не сохраняются как знание.
Провал 9. Тестирование ради активности.
Количество экспериментов важнее качества решений.
Провал 10. Решения без последствий.
Результат теста ни на что не влияет.
Речь, по которой сразу понятно: это плохой PM
«Давайте просто попробуем и посмотрим».
«Если цифры выросли, значит идея хорошая».
«Этот результат странный, давайте его не учитывать».
«Метрику можно поменять, так понятнее».
«Главное, что тест статистически значим».
Эти фразы объединяет одно - отсутствие связи между экспериментом и управленческим выбором. Данные используются как украшение аргументов, а не как основа решений.
Короткий практический кейс с результатом
Команда онлайн-сервиса регулярно запускала A/B-тесты интерфейсных изменений. Почти каждый эксперимент показывал локальный рост отдельных метрик. При этом ключевой показатель удержания оставался стабильным.
PM чувствовал, что эксперименты не дают стратегической ценности, но не мог это доказать. Формально тесты были корректны, статистика сходилась, отчеты выглядели убедительно.
После ретроспективы команда признала, что эксперименты не отвечают на важные вопросы. Тестировались элементы, а не причины поведения. Было решено изменить подход.
Команда начала формулировать один бизнес-вопрос на серию тестов. Все гипотезы должны были объяснять один и тот же пользовательский выбор. Мелкие тесты были объединены в более крупные эксперименты.
Часть тестов показала отсутствие эффекта, и это стало поводом отказаться от привычных решений. Команда перестала оптимизировать детали и перешла к изменениям сценариев.
Через несколько месяцев удержание выросло. Эксперименты стали реже, но каждое решение опиралось на более глубокое понимание поведения пользователей.
Было → сделали → вышло
В B2B-продукте A/B-тесты использовались как аргумент в спорах между командами. Продажи, маркетинг и продукт запускали эксперименты, чтобы подтвердить свою точку зрения.
PM оказался в сложной позиции. Он отвечал за процесс тестирования, но не мог навязать единые правила интерпретации. Один и тот же результат трактовался по-разному.
Решением стало введение простой логики эксперимента как обязательного стандарта. Каждый тест должен был начинаться с бизнес-вопроса и заканчиваться заранее определенным решением.
Это резко сократило количество экспериментов. Многие идеи не проходили проверку на управленческую полезность.
Зато оставшиеся тесты перестали быть инструментом споров. Результаты стали восприниматься как входные данные для решений, а не как доказательства правоты.
Команда отметила снижение конфликтов и рост доверия к данным. A/B-тестирование стало частью управления, а не политической игры.
Список саморефлексии
- Есть ли у эксперимента бизнес-вопрос.
- Зафиксирована ли гипотеза до запуска.
- Понятно ли ожидаемое изменение поведения.
- Выбрана ли ключевая метрика заранее.
- Есть ли критерии принятия решения.
- Может ли результат изменить планы.
- Не меняются ли метрики по ходу теста.
- Анализируются ли побочные эффекты.
- Есть ли договоренность о сегментации.
- Фиксируются ли выводы письменно.
- Используются ли нейтральные результаты.
- Улучшается ли качество гипотез.
- Не подгоняется ли интерпретация.
- Есть ли единый язык анализа.
- Связаны ли тесты с бизнес-целями.
- Не тестируем ли мы ради тестирования.
- Снижается ли неопределенность.
- Помогают ли тесты говорить «нет».
- Влияют ли данные на roadmap.
- Делают ли эксперименты решения проще.
FAQ
Зачем вообще нужна логика A/B-тестирования?
Чтобы эксперименты приводили к решениям, а не к отчетам.
Всегда ли нужен A/B-тест?
Нет, только когда выбор действительно неочевиден.
Опасна ли статистическая значимость?
Да, если она используется без контекста.
Что делать с нулевым результатом?
Использовать его как знание и скорректировать гипотезы.
Кто отвечает за решения по итогам теста?
Те, кто владеют бизнес-результатом.
Можно ли автоматизировать A/B-тестирование?
Инструменты можно автоматизировать, мышление нет.
Почему данные вводят в заблуждение?
Потому что их интерпретируют без логики.
Нужно ли много экспериментов?
Нужно достаточно, чтобы снижать неопределенность.
Когда A/B-тест вреден?
Когда он подменяет мышление цифрами.
Как понять, что эксперименты работают?
Когда решения становятся обоснованнее и проще.
Логика A/B-тестирований определяет их реальную ценность для продукта. Эксперименты начинают помогать принимать решения только тогда, когда они встроены в контур управления и связаны с выбором. Без четкого вопроса, гипотезы и заранее определенного решения данные легко превращаются в инструмент самообмана. Управляемые эксперименты не гарантируют успеха, но они системно снижают неопределенность и делают продуктовые решения осознанными.